Virtualization and HA, Scalability
-
@tim_g said in Virtualization and HA, Scalability:
@kelsey said in Virtualization and HA, Scalability:

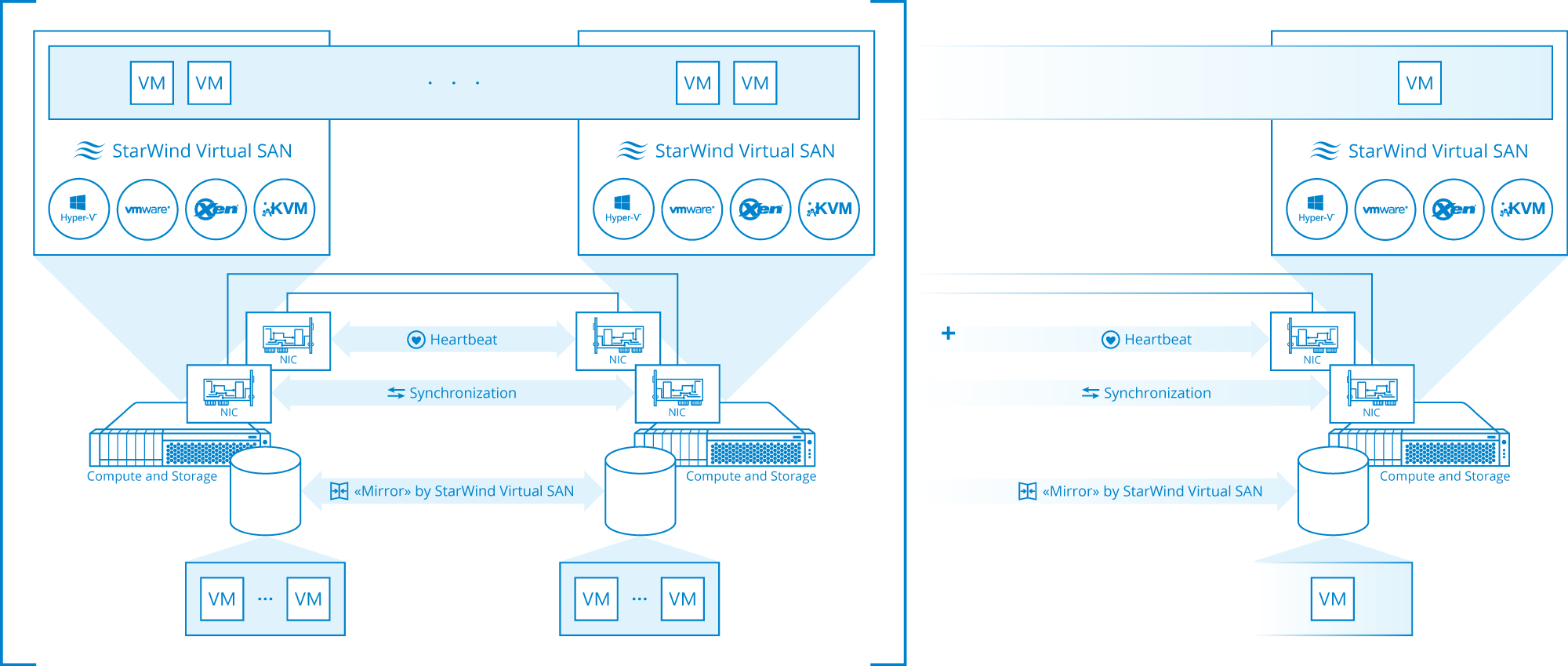
Now with Hyperconvergence, the above example uses local storage inside of physical host #1 and physcal host #2, using some kind of software (like StarWind vSAN or Microsoft's Storage Spaces Direct) that treats the storage in each Host as a single pool of shared storage. (like how in your picture the "storage server" is portrayed, but tha twould go away and would be inside of each physical host)
This way, you have no single point of storage failure.
If host 1 goes down, all data is also on host 2 where everything can continue running after the VMs fail over. Same with if Host2 goes down.
Here's a nice diagram from StarWind, which I've taken without asking. Please forgive me @KOOLER
")
-
@scottalanmiller video here can help explain the difference between IT Buyers and IT Pros, but simply put Buyers don't need to know how everything is set to work together, that is the IT Pros job.
-
@tim_g hi is there a website about scalable for information
-
@kelsey said in Virtualization and HA, Scalability:
@tim_g hi is there a website about scalable for information
In a general sense, or related to a specific product or architecture?
-
@kelsey said in Virtualization and HA, Scalability:
@tim_g hi is there a website about scalable for information
I'm not sure what you're asking.
-
@kelsey said in Virtualization and HA, Scalability:
@tim_g hi is there a website about scalable for information
Pretty much any hyperconvergence vender will have info on their site.
-
So there's another way I don't think I've seen anyone mention. That's doing application level HA. Rather than relying on the hosts to replicate data between each other, you just run multiple instances of a service. Then you have some kind of scheduler decide where the VM needs to live. That could be a person (if you're manually building), your orchestration tool by just defining which machine you want it to run on, or programmatically (like with cloud infrastructure). Then you can use a service discovery tool like Consul to register that service and have it added to your load balancer. Consul also does health checks that you script (for instance if you get anything other than a 200 response from a site it's unhealthy) and then it will auto remove it from the pool of available systems.
-
There's also the container schedulers and service discovery tools like Kubernetes. You define how many pods you want running and Kubernetes handles where all of those should run and takes care of ensuring that many exist. If one goes down, it automatically brings another up in it's place.
-
@stacksofplates said in Virtualization and HA, Scalability:
So there's another way I don't think I've seen anyone mention. That's doing application level HA.
Her professor is making them focus only on platform level. The impression we have is that he's not familiar with HA at all and doesn't know nearly as much as we'd hope that students would already know!
-
@scottalanmiller said in Virtualization and HA, Scalability:
@stacksofplates said in Virtualization and HA, Scalability:
So there's another way I don't think I've seen anyone mention. That's doing application level HA.
Her professor is making them focus only on platform level. The impression we have is that he's not familiar with HA at all and doesn't know nearly as much as we'd hope that students would already know!
Oh my fault. I somehow missed that. Ya good luck doing platform HA with hosted cloud.
-
@scottalanmiller said in Virtualization and HA, Scalability:
@stacksofplates said in Virtualization and HA, Scalability:
So there's another way I don't think I've seen anyone mention. That's doing application level HA.
Her professor is making them focus only on platform level. The impression we have is that he's not familiar with HA at all and doesn't know nearly as much as we'd hope that students would already know!
This is the same in the UK. Lecturers get their content and generally stick to it, they teach. They don't have the skills to actually understand if the content is true, valid, good etc - because if they did, they would work in IT and not teach it.
-
@jimmy9008 said in Virtualization and HA, Scalability:
@scottalanmiller said in Virtualization and HA, Scalability:
@stacksofplates said in Virtualization and HA, Scalability:
So there's another way I don't think I've seen anyone mention. That's doing application level HA.
Her professor is making them focus only on platform level. The impression we have is that he's not familiar with HA at all and doesn't know nearly as much as we'd hope that students would already know!
This is the same in the UK. Lecturers get their content and generally stick to it, they teach. They don't have the skills to actually understand if the content is true, valid, good etc - because if they did, they would work in IT and not teach it.
OP is in the UK
")
But it is same in the US for sure.
-
Hi Kelsey,
First of all, as previously mentioned in the thread, the IPOD scenario is absolutely atrocious no matter how you look at it. You pay more to get more hardware to manage to get lower resiliency. Here is a very short paper on why it's particularly important to have HA or FT in a virtual inrastructure:
https://www.starwindsoftware.com/fault-tolerance-and-high-availability-pageA way to play around IPOD is replicating local storage across the hypervisor hosts. Here is a doc describing how it's done:
https://www.starwindsoftware.com/whitepapers/starwind-virtual-san-whitepaper.pdfAlso, our forums are pretty helpful and you can ask different virtualization, storage, HA questions there:
https://forums.starwindsoftware.com